Bad voice quality often gets blamed on the PBX. The real cause is usually the network path. One weak carrier link can turn clear RTP into broken audio.
An internet carrier is the company that provides the IP connection your SIP and RTP traffic rides on. It controls bandwidth, latency, jitter, loss, public IP options, and the outage response that your voice depends on.

An internet carrier is the “road” your VoIP packets travel on. SIP signaling 1 and RTP media transport 2 do not care about your brand of phone. They care about timing and stability. That is why the carrier choice changes how calls feel during busy hours and during failures.
In many VoIP deployments, there are two outside partners:
- The internet carrier that provides IP connectivity.
- The ITSP (SIP trunk provider) that provides phone numbers and PSTN access.
These partners can be the same company, but often they are not. When they are separate, the call quality you experience depends on how well the internet carrier reaches the ITSP’s SBCs and POPs. This is where Internet peering and routing 3 matter.
Voice traffic has simple needs:
- steady latency
- low jitter
- low packet loss
- enough upstream bandwidth
- predictable public IP behavior
A “fast” internet link can still fail voice if it has unstable jitter. A slower link can still sound great if it is stable and shaped correctly. That is why symmetric bandwidth and consistency matter more than raw download speed.
Carrier design details also show up in real life:
- Carrier-grade NAT (CGNAT) 4 and dynamic IPs can break inbound services or make troubleshooting slow.
- Carrier CPE with SIP ALG can rewrite SIP and cause one-way audio.
- Poor upstream routing can add extra hops and raise delay.
- Bad congestion handling can cause bursts of loss during backups.
Below is a simple way to separate roles when planning and troubleshooting.
| Term | What it means in VoIP | What it controls most |
|---|---|---|
| Internet carrier / ISP | Provides IP connectivity | latency, jitter, loss, public IP, uptime |
| ITSP / SIP trunk provider | Provides telephony services | DIDs, PSTN access, routing, STIR/SHAKEN |
| Backbone / transit | Large upstream networks | long-haul path quality between regions |
| POP | Provider edge location | how close your path is to the SBC |
A short story placeholder helps explain the common failure: a site had “1 Gbps” broadband, but uploads caused bufferbloat 5. Calls sounded fine in the morning, then broke during afternoon backups. The fix was not a new PBX. The fix was the carrier edge design plus traffic shaping.
Now the key is to use correct language so the design stays clean. That starts with the difference between an internet carrier, an ISP, an ITSP, and a backbone.
Some teams call everything a “carrier.” That slows down escalations. Clear roles speed up fixes and make SLA conversations easier.
How does an internet carrier differ from an ISP, ITSP, and backbone?
People often say “the carrier is down” without knowing which carrier. Voice teams then chase the wrong company for hours.
An ISP is the company that sells you last-mile internet access, an internet carrier is the network providing IP transport, an ITSP provides SIP trunks and numbers, and a backbone is the large upstream transit network that carries traffic between major regions.
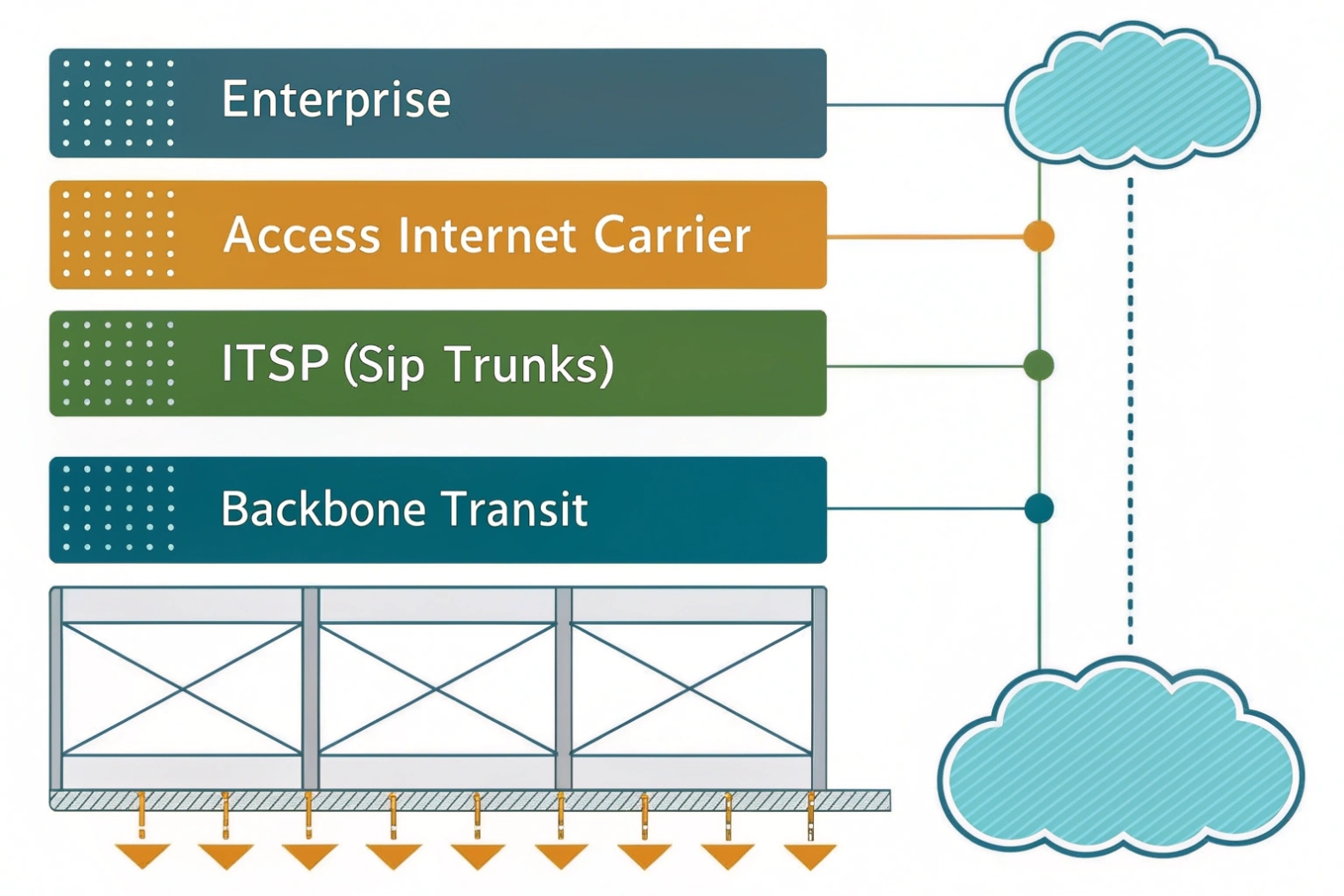
In day-to-day business talk, “internet carrier” and “ISP” often mean the same thing. Both describe the company that delivers your internet circuit to the building. Still, there is a useful technical separation:
- ISP / access carrier: the last mile and the circuit you buy. This includes the handoff, the CPE, and the SLA you pay for.
- Internet carrier network: the provider’s metro and regional IP network behind that circuit. This is where congestion and routing policy live.
- Backbone / transit: the upstream networks that carry traffic between cities and countries. Your ISP may buy transit from several backbones.
- ITSP: the telephony provider. This is the company that terminates calls to the PSTN, hosts SBCs, and provides DIDs, E911, and caller ID services.
A VoIP call can cross all of these:
- Your LAN sends SIP/RTP to the router.
- The ISP last mile carries packets into the provider network.
- Transit/backbone carries packets toward the ITSP.
- The ITSP SBC accepts the trunk and routes the call.
This matters because “who fixes it” depends on where the issue is. High jitter inside your last mile is your ISP. A broken route to one ITSP POP can be a peering issue between networks. A failed call to one country may be an ITSP routing issue, not an internet issue.
| Item | Internet carrier / ISP side | ITSP side |
|---|---|---|
| Main job | IP transport | PSTN access and numbering |
| Key SLA | uptime, loss, jitter, repair time | call completion, SBC availability, route quality |
| Common outage | fiber cut, congestion, CPE failure | SBC failure, carrier route failure, DID issue |
| Best tool | latency/jitter tests, path traces | SIP traces, CDRs, route logs |
When these roles are clear, it becomes easier to choose the right circuit type for voice. Not all “internet” products behave the same for RTP.
Which carrier options fit me—fiber, MPLS, DIA, or broadband?
Many sites buy broadband because it is cheap. Then they try to force it to behave like a voice circuit. Sometimes it works. Sometimes it fails during the worst moment.
Fiber DIA is best when voice uptime and jitter targets matter, MPLS fits private multi-site voice paths, and broadband is fine for small sites when you use QoS shaping and accept best-effort risk.
The right carrier option depends on how critical your phones are and how many calls you carry at peak. It also depends on whether your PBX is on-prem, in a data center, or in the cloud.
Fiber Ethernet and DIA
DIA (Dedicated Internet Access) is a business-grade product. It usually provides:
- symmetric bandwidth options
- public static IPs
- better repair response
- clearer SLAs for packet loss and jitter
For SIP trunks, DIA is the easiest way to keep RTP stable. It also makes inbound peering and IP allowlists simple.
MPLS
MPLS is a private WAN service. It is strong when:
- you have many sites
- you want predictable private routing between sites
- you need a controlled class-of-service across your WAN
MPLS does not automatically solve internet reach to your ITSP. Many designs use MPLS for site-to-core traffic, then break out to the internet at a hub or at local sites. Voice can still be great on MPLS, but the exit design matters.
Broadband can work for voice, but it is best-effort. The biggest risk is not download speed. The biggest risk is:
- upstream congestion
- jitter spikes during uploads
- repair times that are slow
Broadband often needs a good router with traffic shaping to control bufferbloat. For smaller teams, this can be a practical solution.
A simple selection rule
- If the site is a main office, contact center, hospital, or security control room, DIA is often the safer base.
- If the site is a small branch, broadband plus LTE/5G backup can be enough.
- If the site is a large multi-site enterprise, MPLS or SD-WAN with strong policies can be the right middle.
| Option | Best for | VoIP strength | Main risk |
|---|---|---|---|
| Fiber DIA | HQ, call-heavy sites | stable jitter and SLAs | higher cost |
| MPLS | multi-site private WAN | controlled CoS between sites | internet exit design |
| Business broadband | small/medium sites | low cost, fast install | congestion and repair time |
| Dual broadband + backup | branches | good uptime with failover | more config complexity |
Once the circuit type is chosen, the next question is uptime design. A single carrier link is a single point of failure, no matter how good the SLA looks.
Do I need dual carriers, BGP, or SD-WAN for uptime?
Voice is a real-time service. A ten-minute ISP outage feels like a full business stop. Redundancy is not a luxury for many sites.
Dual carriers are the simplest uptime upgrade. BGP is useful for advanced control and true multi-homing, and SD-WAN is often the fastest way to get automatic failover with voice-aware health checks.
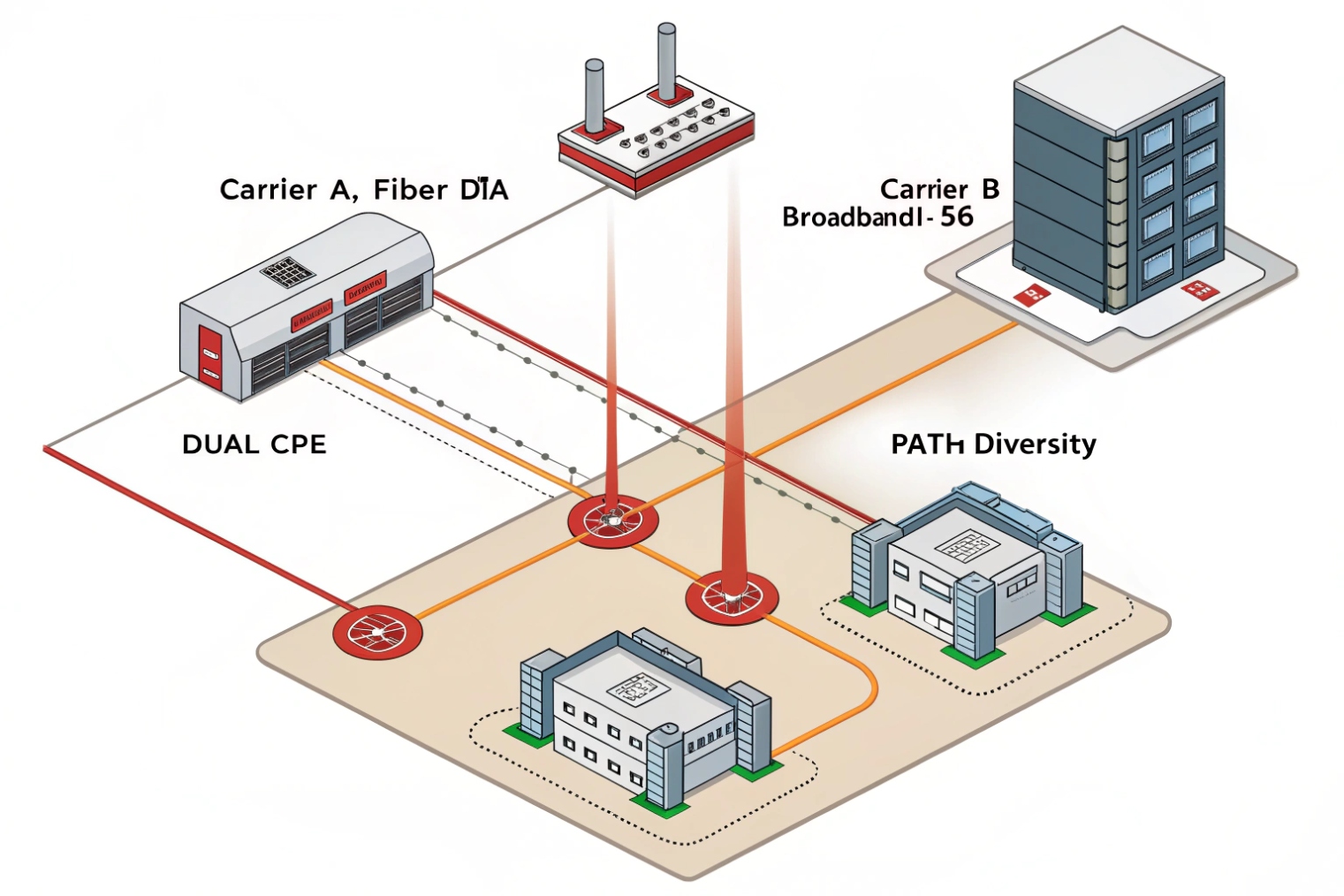
There are three common uptime levels:
Level 1: Single carrier with good monitoring
This is common for small offices. It relies on:
- stable circuit
- quick detection of outage
- manual failover to cellular hotspot when needed
It is cheap, but it is fragile.
Level 2: Dual carriers with simple failover
This is the most practical step for many sites. The design goal is diversity:
- different last-mile paths
- different provider networks
- different entry points into the building when possible
Failover can be handled by:
- a firewall with dual WAN
- SD-WAN appliance
- router policy routing
This keeps calls running during a fiber cut or provider outage.
Level 3: Dual carriers with BGP or SD-WAN plus policy control
Border Gateway Protocol (BGP) multi-homing 6 is useful when you need:
- inbound control
- stable public IP space that survives carrier changes
- active-active routing decisions
Still, BGP adds operational load. It often requires your own ASN and public IP block, and a team that can manage routing safely.
SD-WAN is popular because it can:
- monitor loss, latency, and jitter in real time
- steer voice traffic to the best link
- fail over fast when the primary degrades, not only when it dies
A good SD-WAN policy can keep SIP registration stable and protect RTP. The key is to tune health checks for voice, not only for “internet up.”
| Redundancy method | Good for | What it improves | What to watch |
|---|---|---|---|
| Dual WAN failover | most sites | uptime during outages | ensure diverse paths |
| SD-WAN | multi-site voice | auto steering on jitter/loss | voice policy tuning |
| BGP multi-homing | large enterprises | inbound control, stable addressing | operational complexity |
| LTE/5G backup | branches | fast backup path | data caps and CGNAT |
A simple target is “calls continue during a single failure.” Dual carriers plus SD-WAN often hits that target without the heavy lift of BGP.
Now the last piece is what to demand in writing. SLAs, peering, and QoS language must match voice reality, not just “99.9% uptime.”
What SLAs, peering, and QoS should I require for SIP trunks?
Contracts often talk about uptime. Voice users care about jitter and loss. These are not the same.
Require SLAs that include repair time plus measurable performance targets, ask where the carrier peers with your ITSP, and confirm DSCP handling and traffic shaping support so RTP stays stable during congestion.
SLA items that actually matter for voice
A useful SLA set includes:
- uptime and how it is measured
- mean time to repair targets
- packet loss targets
- jitter targets
- latency targets (especially to your ITSP POP)
- escalation process and response times
Even when a carrier will not commit to strict jitter numbers, asking the question forces clarity on what they will support.
Peering and POP reach
Voice quality is strongly affected by how your packets reach the ITSP SBC. Ask:
- Which POP will your traffic exit from?
- Does the carrier have direct peering with the ITSP?
- Can your SIP trunk register to more than one ITSP POP?
- Will the carrier route to the closest POP, or a fixed one?
A longer route is not always bad, but it raises risk. More hops means more places for congestion and loss.
QoS and DSCP reality
Many VoIP teams mark RTP as DSCP Expedited Forwarding (EF) per-hop behavior 7 and SIP as CS3/AF31. That helps inside the LAN. On the public internet, DSCP may be reset. Some business services preserve DSCP or offer QoS classes. If the carrier offers QoS, confirm:
- DSCP preservation across the circuit
- mapping to provider queues
- how to mark traffic on your side
- if the carrier CPE will shape or police traffic
Also confirm carrier CPE features:
- SIP ALG off
- no hidden traffic shaping that adds delay
- support for static public IPs
- no CGNAT for business voice circuits
A practical acceptance test
Before signing long terms, run tests:
- ping and jitter tests to the ITSP SBC IPs
- sustained upload tests to see bufferbloat impact
- test calls during busy hour
- failover tests if dual carriers exist
| Requirement area | What to ask for | Why it matters for VoIP |
|---|---|---|
| SLA | uptime + MTTR + loss/jitter targets | voice breaks before “down” happens |
| Public IP | static IP, no CGNAT | simpler SIP trunking and support |
| Peering | local POP, direct peering if possible | lower latency and fewer risk points |
| QoS | DSCP handling or CoS option | protects RTP timing |
| CPE policy | SIP ALG disabled, clear firewall behavior | avoids one-way audio and registration issues |
| Reporting | outage notices, circuit stats | faster troubleshooting |
A final placeholder lesson from a multi-site rollout: one carrier had great uptime, but poor peering to the ITSP in one region. Calls sounded fine in one city and bad in another. Switching to a different POP and adding a second carrier solved it quickly.
Conclusion
An internet carrier is the IP foundation for SIP and RTP. Choose stable circuits, demand voice-relevant SLAs, and add redundancy so calls survive outages and congestion.
Footnotes
Bad voice quality often gets blamed on the PBX. The real cause is usually the network path. One weak carrier link can turn clear RTP into broken audio.
An internet carrier is the company that provides the IP connection your SIP and RTP traffic rides on. It controls bandwidth, latency, jitter, loss, public IP options, and the outage response that your voice depends on.
An internet carrier is the “road” your VoIP packets travel on. SIP signaling 1 and RTP media transport 2 do not care about your brand of phone. They care about timing and stability. That is why the carrier choice changes how calls feel during busy hours and during failures.
In many VoIP deployments, there are two outside partners:
- The internet carrier that provides IP connectivity.
- The ITSP (SIP trunk provider) that provides phone numbers and PSTN access.
These partners can be the same company, but often they are not. When they are separate, the call quality you experience depends on how well the internet carrier reaches the ITSP’s SBCs and POPs. This is where Internet peering and routing 3 matter.
Voice traffic has simple needs:
- steady latency
- low jitter
- low packet loss
- enough upstream bandwidth
- predictable public IP behavior
A “fast” internet link can still fail voice if it has unstable jitter. A slower link can still sound great if it is stable and shaped correctly. That is why symmetric bandwidth and consistency matter more than raw download speed.
Carrier design details also show up in real life:
- Carrier-grade NAT (CGNAT) 4 and dynamic IPs can break inbound services or make troubleshooting slow.
- Carrier CPE with SIP ALG can rewrite SIP and cause one-way audio.
- Poor upstream routing can add extra hops and raise delay.
- Bad congestion handling can cause bursts of loss during backups.
Below is a simple way to separate roles when planning and troubleshooting.
| Term | What it means in VoIP | What it controls most |
|---|---|---|
| Internet carrier / ISP | Provides IP connectivity | latency, jitter, loss, public IP, uptime |
| ITSP / SIP trunk provider | Provides telephony services | DIDs, PSTN access, routing, STIR/SHAKEN |
| Backbone / transit | Large upstream networks | long-haul path quality between regions |
| POP | Provider edge location | how close your path is to the SBC |
A short story placeholder helps explain the common failure: a site had “1 Gbps” broadband, but uploads caused bufferbloat 5. Calls sounded fine in the morning, then broke during afternoon backups. The fix was not a new PBX. The fix was the carrier edge design plus traffic shaping.
Now the key is to use correct language so the design stays clean. That starts with the difference between an internet carrier, an ISP, an ITSP, and a backbone.
Some teams call everything a “carrier.” That slows down escalations. Clear roles speed up fixes and make SLA conversations easier.
How does an internet carrier differ from an ISP, ITSP, and backbone?
People often say “the carrier is down” without knowing which carrier. Voice teams then chase the wrong company for hours.
An ISP is the company that sells you last-mile internet access, an internet carrier is the network providing IP transport, an ITSP provides SIP trunks and numbers, and a backbone is the large upstream transit network that carries traffic between major regions.
In day-to-day business talk, “internet carrier” and “ISP” often mean the same thing. Both describe the company that delivers your internet circuit to the building. Still, there is a useful technical separation:
- ISP / access carrier: the last mile and the circuit you buy. This includes the handoff, the CPE, and the SLA you pay for.
- Internet carrier network: the provider’s metro and regional IP network behind that circuit. This is where congestion and routing policy live.
- Backbone / transit: the upstream networks that carry traffic between cities and countries. Your ISP may buy transit from several backbones.
- ITSP: the telephony provider. This is the company that terminates calls to the PSTN, hosts SBCs, and provides DIDs, E911, and caller ID services.
A VoIP call can cross all of these:
- Your LAN sends SIP/RTP to the router.
- The ISP last mile carries packets into the provider network.
- Transit/backbone carries packets toward the ITSP.
- The ITSP SBC accepts the trunk and routes the call.
This matters because “who fixes it” depends on where the issue is. High jitter inside your last mile is your ISP. A broken route to one ITSP POP can be a peering issue between networks. A failed call to one country may be an ITSP routing issue, not an internet issue.
| Item | Internet carrier / ISP side | ITSP side |
|---|---|---|
| Main job | IP transport | PSTN access and numbering |
| Key SLA | uptime, loss, jitter, repair time | call completion, SBC availability, route quality |
| Common outage | fiber cut, congestion, CPE failure | SBC failure, carrier route failure, DID issue |
| Best tool | latency/jitter tests, path traces | SIP traces, CDRs, route logs |
When these roles are clear, it becomes easier to choose the right circuit type for voice. Not all “internet” products behave the same for RTP.
Which carrier options fit me—fiber, MPLS, DIA, or broadband?
Many sites buy broadband because it is cheap. Then they try to force it to behave like a voice circuit. Sometimes it works. Sometimes it fails during the worst moment.
Fiber DIA is best when voice uptime and jitter targets matter, MPLS fits private multi-site voice paths, and broadband is fine for small sites when you use QoS shaping and accept best-effort risk.
The right carrier option depends on how critical your phones are and how many calls you carry at peak. It also depends on whether your PBX is on-prem, in a data center, or in the cloud.
Fiber Ethernet and DIA
DIA (Dedicated Internet Access) is a business-grade product. It usually provides:
- symmetric bandwidth options
- public static IPs
- better repair response
- clearer SLAs for packet loss and jitter
For SIP trunks, DIA is the easiest way to keep RTP stable. It also makes inbound peering and IP allowlists simple.
MPLS
MPLS is a private WAN service. It is strong when:
- you have many sites
- you want predictable private routing between sites
- you need a controlled class-of-service across your WAN
MPLS does not automatically solve internet reach to your ITSP. Many designs use MPLS for site-to-core traffic, then break out to the internet at a hub or at local sites. Voice can still be great on MPLS, but the exit design matters.
Broadband can work for voice, but it is best-effort. The biggest risk is not download speed. The biggest risk is:
- upstream congestion
- jitter spikes during uploads
- repair times that are slow
Broadband often needs a good router with traffic shaping to control bufferbloat. For smaller teams, this can be a practical solution.
A simple selection rule
- If the site is a main office, contact center, hospital, or security control room, DIA is often the safer base.
- If the site is a small branch, broadband plus LTE/5G backup can be enough.
- If the site is a large multi-site enterprise, MPLS or SD-WAN with strong policies can be the right middle.
| Option | Best for | VoIP strength | Main risk |
|---|---|---|---|
| Fiber DIA | HQ, call-heavy sites | stable jitter and SLAs | higher cost |
| MPLS | multi-site private WAN | controlled CoS between sites | internet exit design |
| Business broadband | small/medium sites | low cost, fast install | congestion and repair time |
| Dual broadband + backup | branches | good uptime with failover | more config complexity |
Once the circuit type is chosen, the next question is uptime design. A single carrier link is a single point of failure, no matter how good the SLA looks.
Do I need dual carriers, BGP, or SD-WAN for uptime?
Voice is a real-time service. A ten-minute ISP outage feels like a full business stop. Redundancy is not a luxury for many sites.
Dual carriers are the simplest uptime upgrade. BGP is useful for advanced control and true multi-homing, and SD-WAN is often the fastest way to get automatic failover with voice-aware health checks.
There are three common uptime levels:
Level 1: Single carrier with good monitoring
This is common for small offices. It relies on:
- stable circuit
- quick detection of outage
- manual failover to cellular hotspot when needed
It is cheap, but it is fragile.
Level 2: Dual carriers with simple failover
This is the most practical step for many sites. The design goal is diversity:
- different last-mile paths
- different provider networks
- different entry points into the building when possible
Failover can be handled by:
- a firewall with dual WAN
- SD-WAN appliance
- router policy routing
This keeps calls running during a fiber cut or provider outage.
Level 3: Dual carriers with BGP or SD-WAN plus policy control
Border Gateway Protocol (BGP) multi-homing 6 is useful when you need:
- inbound control
- stable public IP space that survives carrier changes
- active-active routing decisions
Still, BGP adds operational load. It often requires your own ASN and public IP block, and a team that can manage routing safely.
SD-WAN is popular because it can:
- monitor loss, latency, and jitter in real time
- steer voice traffic to the best link
- fail over fast when the primary degrades, not only when it dies
A good SD-WAN policy can keep SIP registration stable and protect RTP. The key is to tune health checks for voice, not only for “internet up.”
| Redundancy method | Good for | What it improves | What to watch |
|---|---|---|---|
| Dual WAN failover | most sites | uptime during outages | ensure diverse paths |
| SD-WAN | multi-site voice | auto steering on jitter/loss | voice policy tuning |
| BGP multi-homing | large enterprises | inbound control, stable addressing | operational complexity |
| LTE/5G backup | branches | fast backup path | data caps and CGNAT |
A simple target is “calls continue during a single failure.” Dual carriers plus SD-WAN often hits that target without the heavy lift of BGP.
Now the last piece is what to demand in writing. SLAs, peering, and QoS language must match voice reality, not just “99.9% uptime.”
What SLAs, peering, and QoS should I require for SIP trunks?
Contracts often talk about uptime. Voice users care about jitter and loss. These are not the same.
Require SLAs that include repair time plus measurable performance targets, ask where the carrier peers with your ITSP, and confirm DSCP handling and traffic shaping support so RTP stays stable during congestion.
SLA items that actually matter for voice
A useful SLA set includes:
- uptime and how it is measured
- mean time to repair targets
- packet loss targets
- jitter targets
- latency targets (especially to your ITSP POP)
- escalation process and response times
Even when a carrier will not commit to strict jitter numbers, asking the question forces clarity on what they will support.
Peering and POP reach
Voice quality is strongly affected by how your packets reach the ITSP SBC. Ask:
- Which POP will your traffic exit from?
- Does the carrier have direct peering with the ITSP?
- Can your SIP trunk register to more than one ITSP POP?
- Will the carrier route to the closest POP, or a fixed one?
A longer route is not always bad, but it raises risk. More hops means more places for congestion and loss.
QoS and DSCP reality
Many VoIP teams mark RTP as DSCP Expedited Forwarding (EF) per-hop behavior 7 and SIP as CS3/AF31. That helps inside the LAN. On the public internet, DSCP may be reset. Some business services preserve DSCP or offer QoS classes. If the carrier offers QoS, confirm:
- DSCP preservation across the circuit
- mapping to provider queues
- how to mark traffic on your side
- if the carrier CPE will shape or police traffic
Also confirm carrier CPE features:
- SIP ALG off
- no hidden traffic shaping that adds delay
- support for static public IPs
- no CGNAT for business voice circuits
A practical acceptance test
Before signing long terms, run tests:
- ping and jitter tests to the ITSP SBC IPs
- sustained upload tests to see bufferbloat impact
- test calls during busy hour
- failover tests if dual carriers exist
| Requirement area | What to ask for | Why it matters for VoIP |
|---|---|---|
| SLA | uptime + MTTR + loss/jitter targets | voice breaks before “down” happens |
| Public IP | static IP, no CGNAT | simpler SIP trunking and support |
| Peering | local POP, direct peering if possible | lower latency and fewer risk points |
| QoS | DSCP handling or CoS option | protects RTP timing |
| CPE policy | SIP ALG disabled, clear firewall behavior | avoids one-way audio and registration issues |
| Reporting | outage notices, circuit stats | faster troubleshooting |
A final placeholder lesson from a multi-site rollout: one carrier had great uptime, but poor peering to the ITSP in one region. Calls sounded fine in one city and bad in another. Switching to a different POP and adding a second carrier solved it quickly.
Conclusion
An internet carrier is the IP foundation for SIP and RTP. Choose stable circuits, demand voice-relevant SLAs, and add redundancy so calls survive outages and congestion.
Footnotes
-
Official SIP spec for understanding registrations, call setup, and common troubleshooting patterns. ↩ ↩ ↩
-
RTP standard that explains media timing, sequencing, and why jitter/loss becomes audible. ↩ ↩ ↩
-
Explains how networks interconnect and why path choices affect latency and call stability. ↩ ↩ ↩
-
Background on CGNAT and why shared public IPs complicate inbound VoIP and diagnostics. ↩ ↩ ↩
-
Definition of bufferbloat and why oversized queues create latency spikes during uploads. ↩ ↩ ↩
-
Overview of BGP multi-homing concepts for redundancy, inbound control, and routing policy. ↩ ↩ ↩
-
Defines EF behavior used for prioritizing real-time voice packets in QoS designs. ↩ ↩ ↩








