
When a remote site phone goes offline, the team often finds out late. The fix becomes a trip, a permit, and a delay that no one wants.
Yes, explosion-proof SIP telephones can be managed from the cloud, but the best design uses a secure device-management layer, strict provisioning controls, and clear data boundaries for OT and safety teams.

A practical cloud-management model for hazardous-area phones
Cloud management is usually “control plane,” not “media plane”
Most plants do not want voice media routed through a public cloud. That is fine. Cloud management can still deliver value when it handles:
-
provisioning and templates
-
firmware lifecycle
-
alarms and health monitoring
-
configuration compliance and audit trails
Calls can stay on the local PBX, SBC, or PAGA controller. The cloud only manages the endpoint settings and status.
Separate voice operations from safety compliance
Explosion-proof phones sit in safety workflows. So cloud management must respect:
-
change control windows
-
approved firmware lists
-
role-based access for operators vs admins
-
audit evidence for every change
This is why a “simple vendor portal” is not enough unless it supports strong governance.
Choose the management architecture that matches your scale
A small site can manage devices locally. A multi-terminal operator needs a cloud or hybrid approach. The clean options are:
-
on-prem provisioning server with optional cloud monitoring
The best choice depends on network policy and data residency needs.
A simple reference architecture
1) Devices enroll with certificates
2) Devices pull templates and firmware rules
3) Devices send health events (online, SIP register, fault, tamper)
4) Admins act through RBAC and approvals
5) Logs go to an audit system with NTP-aligned time
| Layer | What it does | What it should never do |
|---|---|---|
| PBX/SBC (local) | call routing, priority rules | depend on public internet |
| Cloud management | templates, OTA, monitoring | carry RTP media by default |
| Security services | SSO, MFA, audit logs | allow shared admin accounts |
| OT network controls | VLAN, firewall, allowlists | expose devices directly to WAN |
From my work with large SIP deployments, a hybrid model is often the easiest to get approved. Devices stay inside OT VLANs. A secure outbound connection sends telemetry and receives policies.
If the architecture is clear, the next question becomes specific: which cloud options and protocols fit explosion-proof phones.
This matters because the management protocol decides everything else, including how zero-touch provisioning works.
Now let’s go deeper into the cloud options that actually work in industrial reality.
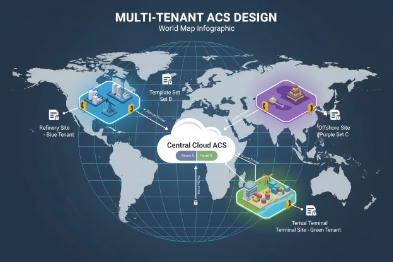
Which cloud options work—multi-tenant ACS, TR-069/TR-369 USP, MQTT/HTTPS APIs, or vendor portals?
Cloud management sounds like one feature. It is really four different approaches with different strengths.
The most common cloud options are multi-tenant device portals, ACS platforms (often tied to TR-069), modern USP (TR-369) systems, and MQTT/HTTPS API-based telemetry. The right choice depends on whether you need strict templates, real-time health events, or deep carrier-grade provisioning.

Multi-tenant cloud portals
A vendor portal is usually the easiest starting point. It often supports:
-
device inventory
-
template-based configuration
-
firmware OTA
-
basic alarms and online status
This works well for distributors and integrators who need fleet management fast. The risk is lock-in and limited integration depth unless the portal has strong APIs.
ACS with TR-069
TR-069 is widely used in telecom device provisioning. In VoIP endpoint projects, an ACS 3 can deliver:
-
consistent provisioning at scale
-
parameter-level control
-
staged configuration updates
This is useful when operators want carrier-grade automation. Still, TR-069 can feel heavy for pure enterprise SIP environments unless the team already uses it.
TR-369 USP for modern device management
USP is designed to improve on older models. It is better suited for:
-
modern telemetry patterns
-
efficient management of many devices
-
more flexible transport
In practice, USP adoption depends on vendor support. When a vendor supports USP well, it can reduce the need for custom scripting.
MQTT and HTTPS APIs
MQTT and HTTPS APIs fit modern industrial integration:
-
MQTT for event streaming and fleet monitoring
-
HTTPS APIs for configuration pushes, queries, and workflows
This approach is great when the customer wants to integrate with their own monitoring stack. It also fits hybrid OT environments where telemetry goes to a central platform.
| Option | Best for | What you gain | Main tradeoff |
|---|---|---|---|
| Vendor portal | quick rollout | UI, templates, OTA | portal lock-in without APIs |
| TR-069 ACS | carrier-style provisioning | deep parameter control | heavier deployment and policy work |
| TR-369 USP | modern endpoint management | efficient fleet control | depends on device support maturity |
| MQTT/HTTPS | integration-first customers | flexible data and automation | needs stronger in-house engineering |
When selecting an option, the key is not the protocol name. The key is the operating model: who approves changes, who owns uptime, and how logs are stored.
Once the management option is chosen, zero-touch provisioning becomes the next requirement. Without ZTP, cloud management is always half manual.
How is zero-touch provisioning deployed at scale—DHCP options, auto-enrollment, device certificates, and role-based access?
Manual provisioning does not scale in terminals and refineries. It also creates drift between batches.
Zero-touch provisioning at scale uses DHCP options or provisioning URLs, auto-enrollment workflows, device certificates for identity, and role-based access so only approved staff can push templates and firmware.
Start with network-based discovery
Common ZTP building blocks include:
-
DHCP for IP and gateway
-
DHCP options that point to provisioning and NTP servers
-
DNS entries that resolve a provisioning hostname
-
optional VLAN assignment and LLDP 4 policies on access switches
A device should boot, find the provisioning endpoint, and enroll without a technician typing URLs.
Auto-enrollment: keep it controlled
Auto-enrollment should not mean “any device can join.” A safe model uses:
-
a pre-approved device list (serial/MAC allowlist)
-
or a certificate-based identity
-
plus a limited enrollment window or token
This stops rogue devices from joining the voice network. It also keeps audits simple.
Device certificates: the clean identity method
Certificates help because:
-
the device can prove identity to the cloud
-
the cloud can prove identity to the device
-
management traffic can stay encrypted with mutual trust
In industrial projects, certificate lifecycle must be simple:
-
clear validity period
-
renewal process
-
replacement process during RMA swaps
RBAC and approvals
Provisioning is a change. In safety environments, changes need control. A practical RBAC 5 model is:
-
Operator: view-only, acknowledge alarms
-
Maintenance: limited actions like remote reboot and diagnostics
-
Admin: template edits and firmware staging
-
Security: audit review and policy enforcement
| ZTP element | What to implement | Why it reduces field time |
|---|---|---|
| DHCP provisioning pointer | automatic URL discovery | no manual entry |
| Auto-enrollment gate | allowlist or token | prevents unauthorized joins |
| Certificates | device identity and mTLS | prevents spoofing |
| Template versioning | staged rollouts | avoids configuration drift |
| RBAC | least privilege | prevents accidental outages |
In large projects, ZTP also improves MTTR. A swapped unit can come online and pick the right template in minutes. That matters when the phone is part of an emergency path.
After ZTP, the next question becomes what can actually be managed remotely. Cloud management must be more than a device list.
What can be managed remotely—firmware OTA, configuration templates, whitelist/dry contacts, alarms, and real-time health monitoring?
If the cloud can only reboot devices, the ROI is weak. The value comes from reducing travel, preventing outages, and keeping compliance stable.
Remote management can cover firmware OTA, configuration templates, dial plan and whitelist controls, dry-contact behavior rules, alarm thresholds, and real-time health monitoring such as SIP registration, link state, temperature warnings, and tamper events.
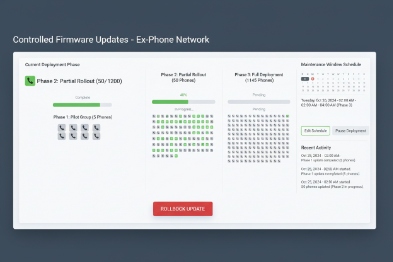
Firmware OTA with staged control
OTA is the biggest risk and the biggest gain. A safe OTA design includes:
-
staged rollout by site and by device group
-
maintenance windows
-
automatic rollback rules when failures exceed a threshold
-
a “known good” firmware list approved by the customer
This prevents a fleet-wide outage caused by one bad build.
Configuration templates and compliance locks
Templates should manage:
-
SIP server addresses and failover
-
codecs and SRTP policy
-
VLAN tags and QoS markings (where supported)
-
button maps and emergency speed dials
-
paging groups and multicast settings
Compliance locks help keep critical parameters from being edited locally. This reduces drift.
Managing whitelists and dial permissions
In many terminals, a phone must call only approved groups. A cloud platform can push:
-
allowed destination lists
-
emergency call routing priority
-
restricted dialing patterns
-
local hotline behavior
This reduces misuse and keeps response workflows consistent.
Dry-contact and alarm logic
For phones with I/O, remote settings can define:
-
relay trigger events (emergency key, call connected, DTMF)
-
pulse duration and latching behavior
-
input debounce time and alarm thresholds
-
tamper and fault reporting
This is useful when the site changes beacon behavior or adds PAGA triggers.
| Remote function | Why it matters in harsh sites | What to require |
|---|---|---|
| OTA firmware | security fixes and stability | staged rollout + rollback |
| Templates | consistent config | versioned templates + audit logs |
| Whitelists | control call behavior | role-based editing |
| I/O rules | strobe and PAGA triggers | event mapping and test mode |
| Health monitoring | faster detection | SIP reg + link + fault events |
Real-time health monitoring
A practical health dashboard should show:
-
online/offline and last seen
-
SIP registration state
-
PoE power cycle events
-
fault and tamper alarms
-
last configuration change
-
NTP sync state for audit logs
At DJSlink, the projects that run best are the ones where maintenance sees problems before operations complains. Health monitoring is the tool that makes that happen.
Remote management delivers value only when the security and compliance model is strong. Industrial buyers will ask for proof. The next section covers the controls that usually decide approval.
How are security and compliance ensured—TLS 1.2/1.3, SSO (SAML/OIDC), audit trails, data residency, and SLA uptime?
A cloud portal without governance becomes a liability. In hazardous sites, it can also become a blocker that the OT team refuses.
Security and compliance depend on encrypted transport (TLS 1.2/1.3), strong identity (SSO via SAML/OIDC), audit trails for every action, clear data residency options, and an SLA that matches operational risk. The safest models use outbound-only connections from OT to cloud and strict allowlists.
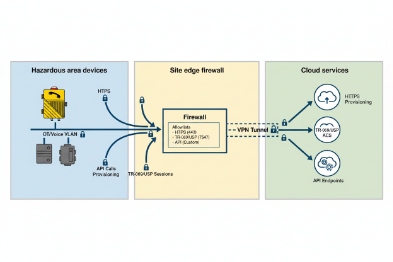
Transport security and certificate hygiene
Management traffic should be encrypted with TLS. For higher trust, mutual TLS helps. The device should also support:
-
certificate validation
-
secure key storage
-
simple certificate rotation workflows
The goal is simple: no plaintext passwords, no weak session handling.
SSO and least privilege
Industrial customers often require central identity:
This keeps admin access controlled even when staff changes.
Audit trails that stand up to incident reviews
Audit trails should record:
-
who changed what
-
when the change happened
-
what device group was affected
-
what the old value and new value were
-
what approval path was used
Audit logs should be exportable to a SIEM or compliance tool. Logs should be NTP-aligned to the site time reference.
Data residency and customer boundaries
Many customers want:
-
region selection for storage
-
private cloud deployment options
-
data minimization (only device metadata, not voice)
-
retention rules that match policy
A strong vendor states clearly what data is stored and what is not stored. Voice media should stay local unless the customer explicitly chooses otherwise.
SLA uptime and offline behavior
Even strong clouds have outages. So the phone must keep working offline:
-
the last known configuration remains active
-
calls still route via the local PBX/SBC
-
alarms still work locally
-
cloud sync resumes when connectivity returns
A practical policy includes an offline drift threshold for device time and config sync, plus alarms when devices have not checked in for too long.
| Compliance control | What to require | Why it gets approved |
|---|---|---|
| TLS 1.2/1.3 | encrypted management channel | prevents sniffing |
| SSO (SAML/OIDC) | central identity + MFA | reduces account risk |
| Audit trails | immutable change logs | supports investigations |
| Data residency | region selection or private option | meets policy and law |
| SLA + offline mode | defined uptime and local fallback | avoids operational dependence |
When these controls are documented, cloud management becomes acceptable even for conservative OT teams. The project then scales across multiple terminals without losing control.
Conclusion
Cloud management works when devices enroll securely, templates and OTA are controlled, monitoring is real-time, and compliance is enforced with SSO, audit logs 8, and clear data boundaries.
Footnotes
-
[Over-The-Air technology for wirelessly distributing new software updates or configurations to devices.] ↩
-
[Virtual Private Cloud, an isolated cloud network hosted within a public cloud environment.] ↩
-
[Auto Configuration Server used in TR-069 protocol to remotely manage customer-premises equipment.] ↩
-
[Link Layer Discovery Protocol used by network devices to advertise their identity and capabilities.] ↩
-
[Role-Based Access Control restricting system access to authorized users based on their role.] ↩
-
[Security Assertion Markup Language, an open standard for exchanging authentication and authorization data.] ↩
-
[OpenID Connect, an identity layer on top of the OAuth 2.0 protocol for verifying end-user identity.] ↩
-
[Chronological records of system activities ensuring traceability and accountability for security compliance.] ↩








