Mislabel the provider role and everything gets messy: calls fail, porting stalls, E911 breaks, and blame loops forever.
A VoIP service provider is the external party that connects your PBX or UC platform to the public phone world, delivers numbers and routing, and enforces identity, emergency, security, and service quality policies.

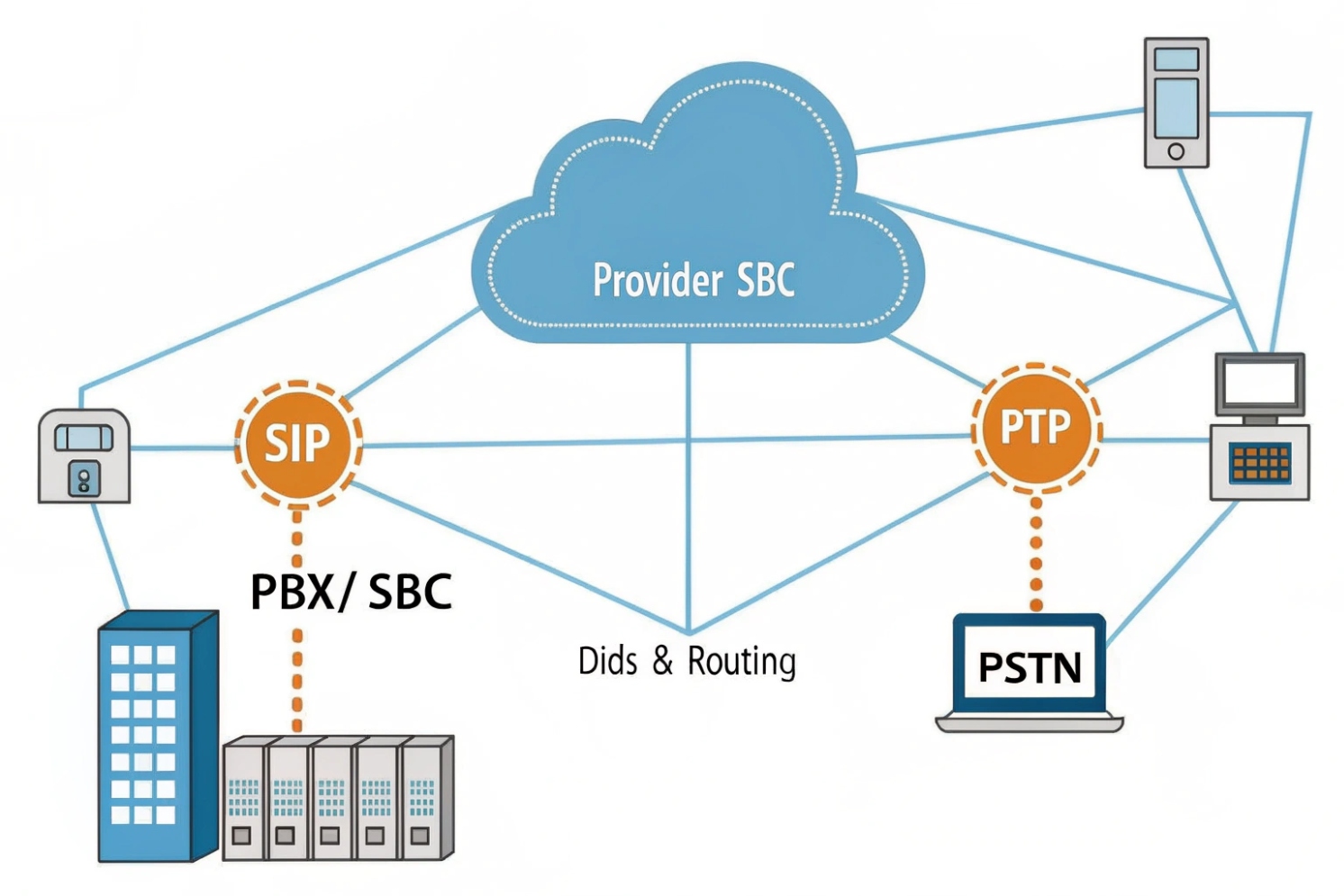
Where does the service provider sit in the call path?
The “outside world” bridge: origination and termination
In a normal enterprise VoIP design, the PBX (or cloud PBX) handles users, extensions, dial plans, and internal calling. But it cannot magically reach the PSTN. The service provider is the bridge. They provide inbound origination (someone calls your DID and it reaches your PBX) and outbound termination (your PBX sends a call to them, and they deliver it to the destination network). That is why many teams call them an ITSP or SIP trunk provider. The job stays the same even when the branding changes.
Numbers, routing, and policy are the real product
A lot of people describe the service as “SIP trunks.” That is only the interface. The real service is what happens behind that interface:
- They allocate and manage Direct Inward Dialing numbers (DIDs) 1{#fnref2}, toll-free, sometimes short codes where permitted.
- They handle Local Number Portability (LNP) and number porting 2{#fnref3} and map inbound numbers to your SIP trunk or registration.
- They route outbound calls worldwide using downstream carriers and route policies (least-cost or quality-based).
- They provision emergency calling and bind numbers to service addresses (E911/112) so calls reach the right PSAP, including VoIP 911 and E911 service address workflows 3{#fnref4}.
- They enforce caller identity features like CLI/CNAM and STIR/SHAKEN caller ID authentication 4{#fnref5} to reduce spoofing and raise answer rates.
- They define codec support, DTMF methods, and media handling, which impacts transcoding and call quality.
- They protect the edge with Session Border Controller (SBC) behavior 5{#fnref6}: TLS/SRTP, authentication, IP allow-lists, topology hiding, flood and fraud mitigation.
- They govern capacity via channels or CPS limits, bursting rules, throttles, and fraud thresholds.
- They expose portals and APIs for provisioning, routing rules, CDRs, live traces, alerts, and 24/7 support.
What you own vs what they own
The cleanest way to avoid confusion is to draw a boundary line. The provider owns the Public Switched Telephone Network (PSTN) 6{#fnref1} interconnect, numbering resources, routing fabric, and edge security posture. The enterprise owns the PBX, LAN/WAN, endpoint quality, and dial plan logic.
| Layer | You own | Provider owns | Common failure mode |
|---|---|---|---|
| Users & endpoints | IP phones, softphones, Wi-Fi/LAN QoS | N/A | Jitter from Wi-Fi blamed on “carrier” |
| Call control | PBX/UC platform, dial plan | N/A | Bad normalization breaks E.164 |
| Trunk edge | SBC rules (if you run one), NAT design | Provider SBC, ingress/egress policy | One-way audio from NAT mismatch |
| Numbers | Inbound mapping in PBX | DID inventory, LNP, CNAM baseline | Port completes but route not updated |
| PSTN reach | N/A | Downstream carriers, global routing | Low-quality route chosen to save cost |
| Compliance | Local configs, address collection | E911/112 routing, STIR/SHAKEN, lawful policies | Emergency call fails due to stale address |
When this boundary is clear, troubleshooting gets faster and vendor conversations get calmer.
If this still feels abstract, the next sections break it down into practical choices: terminology, the service checklist, how to test quality, and what “global-ready” really means.
How does a VoIP service provider differ from a carrier or ITSP?
People mix these terms because real-world companies mix the roles. That confusion costs time during outages and procurement.
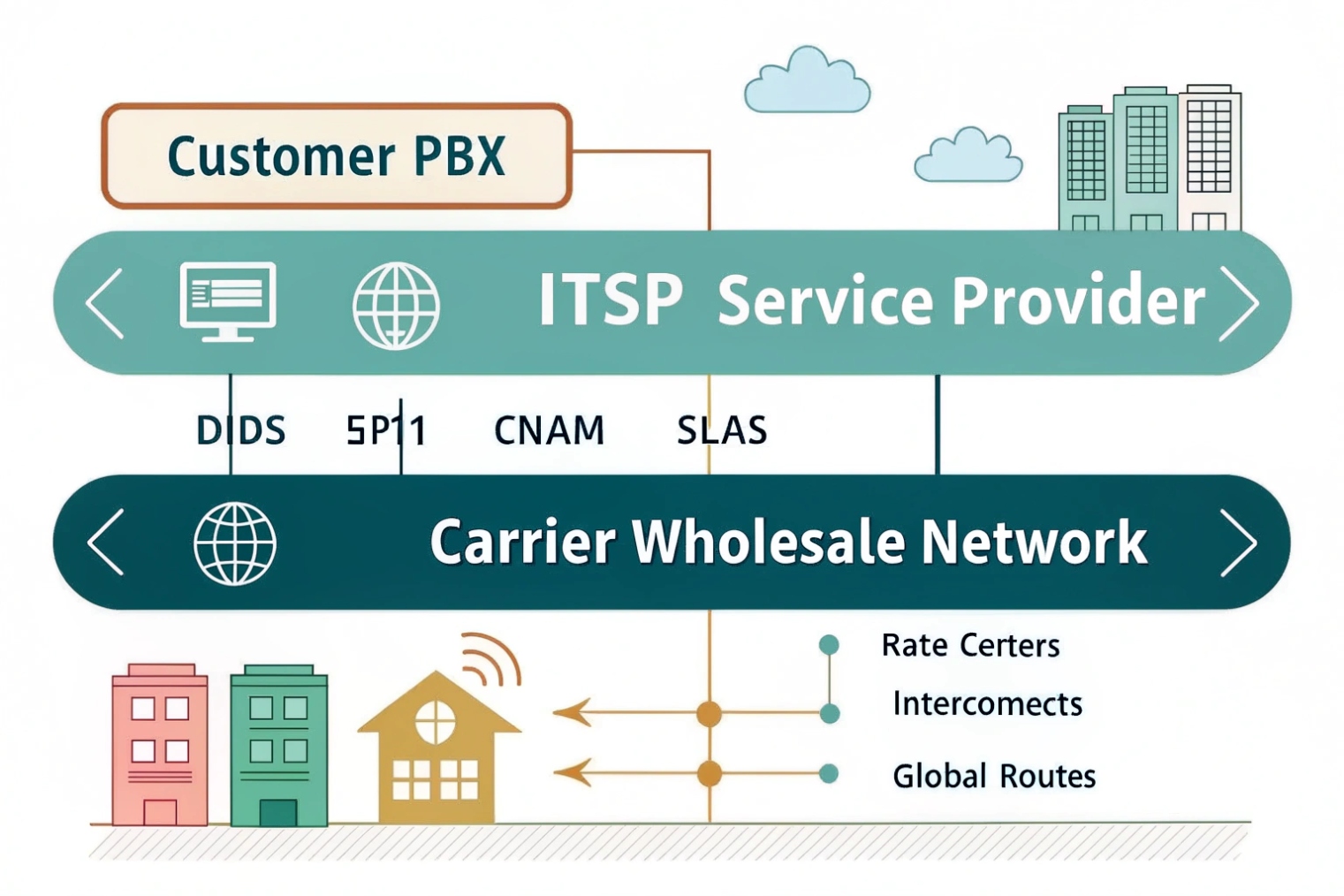
An ITSP is usually the VoIP-facing service layer selling SIP trunks and numbers; a carrier often implies network ownership or regulated PSTN connectivity; one company can be both, but the responsibilities must be written and tested.
The practical definitions that matter in deployments
In day-to-day projects, the useful distinction is not marketing. It is: who controls numbering, who can port, who signs the E911 responsibility, who provides STIR/SHAKEN, and who owns the transport and POP footprint.
- Carrier (traditional sense): Often a facilities-based operator or a regulated voice carrier. They may own last-mile access, switches, or interconnect agreements.
- ITSP (Internet Telephony Service Provider): Often focuses on SIP trunks, VoIP origination/termination, portals, APIs, and VoIP-specific features. They may buy wholesale routes from multiple carriers.
- SIP trunk provider: A commercial label that can describe either of the above.
- UCaaS provider: Delivers a full PBX service plus PSTN connectivity. In that model, the “provider” may include both the PBX and the trunk.
The key is not what they call themselves. The key is whether they can prove control over the functions you need, and whether those functions are backed by a measurable SLA.
Why the distinction changes your risk model
If your provider is mainly reselling wholesale routes, quality can swing when they change downstream partners. That is not always bad, but the controls must exist: route classes, quality-based routing, and transparent reporting. If your provider is a direct carrier, there may be stronger control in certain regions, but not necessarily better global coverage. Many strong providers blend both approaches: direct interconnect where they have it, wholesale where it makes sense.
| Term you hear | What it usually means | What to verify | What to put in the contract |
|---|---|---|---|
| “Carrier-grade” | Marketing claim | POP list, redundancy design, NOC process | Uptime, MTTR, escalation path |
| “ITSP” | VoIP feature focus | STIR/SHAKEN, E911, APIs, SBC posture | Feature responsibilities and timelines |
| “Wholesale routes” | They buy from others | Route quality controls, vendor diversity | Quality targets and reporting cadence |
| “UCaaS” | PBX + PSTN bundle | Porting ownership, number custody, exit plan | Data export, port-out support, notice periods |
When teams align on these definitions early, vendor selection becomes a technical decision instead of a branding debate.
What services should my provider include—SIP trunks, DID, E911, CNAM?
A provider that “just gives trunks” often creates hidden work later: emergency compliance, caller ID failures, porting gaps, and support that stops at the demarc.
At minimum, the provider should deliver reliable PSTN connectivity plus numbering, porting, emergency calling, and caller identity controls; everything else is a risk and cost multiplier during go-live and outages.

The baseline bundle for serious business calling
For most business deployments, the non-negotiables are:
- SIP trunks (or SIP registrations): Clear interop profile, supported codecs, DTMF method, and NAT guidance.
- DIDs and inbound routing: Number inventory, predictable ordering, and simple mapping rules (per DID, per block, per trunk group).
- Outbound routing controls: E.164 normalization expectations, emergency call patterns, toll restrictions, and per-site policies.
- E911/112 support: Address binding workflows, validation, update processes, and test procedures.
- CNAM / caller ID: Rules for outbound CLI, CNAM storage where applicable, and privacy flags.
- STIR/SHAKEN: Attestation options and guidance to improve answer rates and reduce spam labeling.
Then come the “often needed” items: toll-free, SMS (where permitted), fax passthrough guidance, robocall mitigation tools, per-user or per-trunk fraud controls, and real-time analytics.
Interop details that prevent quality issues
Codec and media handling are where good designs stay clean. If the provider forces transcoding, audio quality drops and troubleshooting becomes guesswork. A well-defined interop profile should state:
- Codec set and priority (and whether G.711 is required).
- DTMF method (RFC2833/4733 vs SIP INFO).
- Early media behavior and ringback.
- SRTP/TLS support and cipher expectations.
- Session timers, re-INVITEs, and NAT keepalives.
| Service item | Why it matters | Questions to ask |
|---|---|---|
| SIP trunk interop profile | Prevents codec/DTMF surprises | “Do you publish a tested profile for my PBX?” |
| DID inventory & blocks | Easier scaling and porting | “Can I order contiguous blocks and reserve?” |
| LNP/porting operations | Smooth migrations | “Do you provide CSR/LOA templates and status updates?” |
| E911/112 workflow | Compliance and safety | “How do you validate and store service addresses per DID?” |
| CNAM and CLI rules | Answer rates and trust | “How do you handle outbound CNAM and privacy flags?” |
| STIR/SHAKEN | Reduces spoofing and spam tags | “What attestation levels can you support for my numbers?” |
| Fraud controls | Protects spend and reputation | “What thresholds, alerts, and blocks exist by default?” |
| Portals + APIs | Faster ops at scale | “Can I automate provisioning, routes, and reports?” |
The right checklist turns “provider selection” into a predictable engineering step, not a gamble.
How do I evaluate SLAs, QoS, and redundancy across POPs?
A cheap trunk that drops calls during peak hours is not cheap. The real cost shows up in lost deals, missed emergency calls, and endless troubleshooting calls.
Evaluate SLAs with measurable voice metrics, verify QoS with real call tests, and demand multi-POP design with automatic failover; resilience must be engineered, not promised.
SLAs: look past “uptime” and ask for voice outcomes
Many SLAs focus on network availability. Voice needs more. Useful agreements include:
- Uptime for SIP signaling and media services (per POP if possible).
- MTTR or clear incident response timelines.
- Post-dial delay targets (how fast the far end rings).
- Quality targets like Mean Opinion Score (MOS) 7{#fnref7} range, or at least a commitment to investigate drops and severe jitter.
- Escalation paths to a 24/7 NOC with defined severity levels.
Even if MOS is not contractually guaranteed, a good provider will supply consistent reporting and accept responsibility at the edge they control.
QoS: measure from your edge to their edge
QoS is shared. The provider can keep their network clean, but if your WAN is congested, voice suffers. The evaluation method should include:
- Controlled test calls at busy hours, not only during lab windows.
- RTP stats capture (packet loss, jitter, RTT) from your SBC/PBX.
- Call completion metrics (ASR, ACD) by destination type.
- Short burst tests for CPS and channel limits to see throttling behavior.
POP redundancy: what “multi-POP” must mean
A POP list is not redundancy unless your trunk can fail over without manual work. Look for:
- Multiple POPs per region with independent upstream paths.
- Geo-DNS or SBC routing that can steer sessions automatically.
- Support for dual registrations or multiple SIP endpoints.
- Clear guidance for PBX/SBC failover timers and retry logic.
| Area | What “good” looks like | How to verify | Red flags |
|---|---|---|---|
| Uptime SLA | Separate targets for signaling and media | Ask for historical incident summaries | One blanket “99.9%” with no detail |
| MTTR & support | 24/7 NOC, severity matrix | Test a ticket and escalation | “Email only” or slow response windows |
| Call setup speed | Stable post-dial delay | Place test calls to key regions | Random long delays during peak |
| RTP quality | Low loss and stable jitter | Capture RTP stats and MOS estimates | Provider blames everything immediately |
| POP resilience | Auto failover across POPs | Simulate a POP outage in a test window | Failover requires manual route change |
| Capacity behavior | Clear channel/CPS limits | Run controlled burst tests | Silent throttling, no alerts |
Treat this as an engineering validation, not a sales conversation. A provider that welcomes testing is usually the safer choice.
Can my provider support number porting, STIR/SHAKEN, and global routing?
Teams often assume these are “basic.” In practice, each depends on paperwork, regional rules, and how the provider connects to other networks.
A capable provider should run LNP end-to-end, support STIR/SHAKEN attestation for your number ownership, and offer predictable global routing with regional compliance—plus clear documentation and operational support.
Number porting: the operational maturity test
Porting is where provider maturity shows. Smooth LNP needs:
- Clear LOA/CSR processes and realistic timelines per country.
- Porting status updates that a project manager can use.
- Temporary routing during cutover if needed.
- Immediate inbound route activation on completion, with verification steps.
A good provider treats porting like a structured project, not a support ticket.
STIR/SHAKEN: identity depends on proof, not desire
STIR/SHAKEN is about caller identity trust. Providers must decide what attestation they can assign based on how you obtained and control the calling number. Practical questions include:
- Can they issue higher attestation when numbers are on-net and assigned to you?
- Do they support enterprise signing models, or is it all provider-signed?
- How do they handle third-party numbers, forwarded calls, and multi-site deployments?
Even with perfect STIR/SHAKEN, your call reputation also depends on consistent CLI, low complaint rates, and sane outbound patterns. The provider’s tools should help enforce that.
Global routing: local presence vs wholesale reach
“Global routing” can mean two very different things:
- Global termination: They can deliver calls to many countries.
- Global origination: They can provide local DIDs in many countries with compliant registration.
Origination is harder because local regulators may require address proof, business registration, or in-country presence. Termination may be wide but uneven in quality unless the provider uses quality-based routing and monitors route performance.
| Capability | What it depends on | What to ask | Common pitfall |
|---|---|---|---|
| LNP / port-in | Paperwork, upstream coordination | “Who owns the porting process end-to-end?” | Provider blames “the losing carrier” with no progress |
| Port-out support | Number custody and account controls | “Can I port out without penalties or delays?” | Hidden lock-in terms |
| STIR/SHAKEN attestation | Number assignment proof | “What attestation will my outbound CLI receive?” | Low attestation leads to spam labeling |
| Global termination quality | Route monitoring and diversity | “Do you offer quality-based routing by region?” | Least-cost routes cause low ASR |
| Global DID availability | Local regulation and inventory | “What docs are needed per country?” | Assuming every country is like the US |
| Emergency calling by region | Local emergency frameworks | “How do you handle E112/E999 equivalents?” | Applying US E911 assumptions globally |
If the provider can clearly answer these questions and back them with tools, tickets, and test results, global expansion becomes a planned rollout instead of a series of surprises.
Conclusion
A VoIP service provider is the PSTN bridge and the policy engine. Pick one that proves porting, identity, emergency, quality, and redundancy in writing and in tests.
Footnotes
-
Defines DIDs and how providers allocate and route numbers to your PBX. ↩ ↩
-
FCC guide to porting numbers between providers and common requirements that delay cutovers. ↩ ↩
-
FCC overview of VoIP 911 obligations and how E911 address registration affects routing. ↩ ↩
-
Explains STIR/SHAKEN and how caller ID authentication reduces spoofing and spam labeling. ↩ ↩
-
IETF reference on SBC functions like topology hiding, NAT traversal, and policy enforcement at the VoIP edge. ↩ ↩
-
Background on PSTN and why a provider’s interconnect matters for origination and termination. ↩ ↩
-
ITU terminology for MOS so you interpret voice-quality reports consistently across providers and tools. ↩ ↩








